

图论
图的种类
主要分为有向图和无向图,注意无向图是特殊的有向图
有向图:a -> b
树是一种有向无环图
无向图:a — b (a -> b && b -> a)
注意无向图在建图时,需要建两条方向相反的边
图的基本概念
入度:一个点有几条边进来
出度:一个点有几条边出去
稀疏图:若一张图的边数远小于其点数的平方,那么它是一张稀疏图 (sparse graph)
稠密图:若一张图的边数接近其点数的平方,那么它是一张稠密图 (dense graph)

有向图的存储方式
邻接矩阵(稠密图)
使用一个二维数组 adj 来存边,其中 adj[u][v] 为 1 表示存在 u 到 v 的边,为 0 表示不存在.如果是带边权的图,可以在 adj[u][v] 中存储 u 到 v 的边的边权。
邻接矩阵只适用于**没有重边(或重边可以忽略)**的情况
其最显著的优点是可以 𝑂(1) 的查询一条边是否存在
一般只会在稠密图上使用邻接矩阵。
邻接表/链式前向星(稀疏图)
前置知识:
使用一个支持动态增加元素的数据结构构成的数组,如 vector<int> adj[n + 1] 来存边,其中 adj[u] 存储的是点 u 的所有出边的相关信息(终点、边权等)
链式前向星,即对图中的每个点开一个单链表以实现邻接表,存储相关信息(忽略顺序)插入一般插在头节点后
//假设有N个点int h[N], e[2 * N], ne[2 * N], idx; // 构成要素与单链表相同
void add(int a, int b) // 单链表的头插{ e[idx] = b; ne[idx] = h[a]; h[a] = idx; idx++;}
memset(h, -1, sizeof h); // 初始化时,让N个头结点全部指向空有向图的遍历
深度优先遍历
...bool st[N]; // 一般情况下,一个点只需遍历一次...void dfs(int u){ st[u] = true; // 标记该点已经被搜过
// 遍历以该点为头节点的单链表,即点u的所有出边 for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; // 存储节点i对应的在图中的编号
if (!st[j]) // 如果这个点没被搜过,就一直搜下去 dfs(j); }}广度优先遍历
注:由于 BFS 的特性,当某个节点第一次被遍历到时,路径一定是最短的
此处 BFS 框架与 BFS 搜索相同
void bfs(){ q.push(1);
memset(d, -1, sizeof d); // 初始化所有距离为-1 d[1] = 0;
while (!q.empty()) { int st = q.front(); q.pop();
for (int i = h[st]; i != -1; i = ne[i]) { int j = e[i]; if (d[j] == -1) { d[j] = d[st] + 1; q.push(j); } } }}
memset(h, -1, sizeof h); // 初始化所有邻接表拓扑排序
前置知识: 若一个由图中所有点构成的序列 A 满足:对于图中的每条边 (x,y),x 在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。(所有的边都是从前指向后的) 注意到如果图里有环,则一定无法构成拓扑序列 存在已被证明的性质:一个有向无环图至少存在一个入度为 0 的点(反证法) 拓扑排序是对一个有向无环图进行的排序过程,使得图中所有顶点的先后顺序满足其与其他顶点的依赖关系。 通过拓扑排序,可以找出图的先后关系。
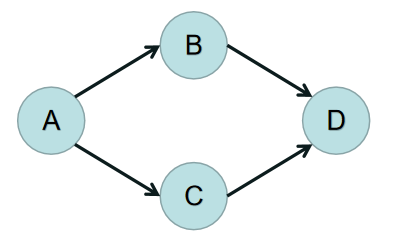
判断有向无环图(能否拓扑排序)的思路:(队列等价于集合)
- 统计全部点的入度,把所有入度为 0 的点入队
- 每次从队列中取一个点 u,删掉点 u 的所有边(u,v1), (u,v2), (u,v3)…
- 判断点 v 的入度,如果入度为 0,将 v 也入队
- 重复上述过程,直到队列为空。
- 如果所有点都进过队列(此时图里没有边),则代表可以拓扑排序
代码
// Problem: 有向图的拓扑序列// Contest: AcWing// URL: https://www.acwing.com/problem/content/850/// Time: 2026-01-23 20:58:12// 拓扑排序不要用STL!// Powered by CP Editor (https://cpeditor.org)#include <algorithm>#include <cstring>#include <iostream>
using namespace std;
const int N = 100010;
int n, m;int h[N], e[N], ne[N], idx;int d[N]; // 统计入度int q[N];
void add(int a, int b){ e[idx] = b; ne[idx] = h[a]; h[a] = idx++;
d[b]++; // 插入了一条边,b的入度+1}
bool topsort(){ int hh = 0, tt = -1; for (int i = 1; i <= n; i++) { if (!d[i]) q[++tt] = i; }
while (hh <= tt) { int t = q[hh++];
for (int i = h[t]; i != -1; i = ne[i]) { int j = e[i]; d[j]--; if (d[j] == 0) q[++tt] = j; } }
if (tt == n - 1) // 所有的数都进过一次队列 return true; // 队列里的数是所有入度为0的点,即为拓扑序列 else return false;}int main(){ cin >> n >> m;
memset(h, -1, sizeof h);
for (int i = 0; i < m; i++) { int a, b; cin >> a >> b; add(a, b); }
if (topsort()) { for (int i = 0; i < n; i++) printf("%d ", q[i]); } else { printf("-1\n"); }}判断图中的负环(SPFA)
思路
在开 dist[] 存储距离的同时,开一个 cnt[],存储从 1 号点走到 x 号点的最短路(边数)。
假如出现了 cnt[x] >= n,说明从 1 号点到 x 号点经过了 n+1 个点,根据抽屉原理,一定存在一个环,且由于 SPFA 的逻辑是“最短”,所以该环一定是负环。
代码
// Problem: spfa判断负环// Contest: AcWing// URL: https://www.acwing.com/problem/content/854/// Time: 2026-01-26 19:34:37//// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;const int N = 100010;
int n, m;int h[N], e[N], ne[N], idx;int dist[N], w[N], cnt[N];bool st[N];
void add(int a, int b, int c){ e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++;}
bool spfa(){ // 求是否存在负环,无需初始化 queue<int> q;
for (int i = 1; i <= n; i++) // 由于负环的起点不一定是1,所以需要把所有点都放进队列里 { st[i] = true; q.push(i); }
while (q.size()) { int t = q.front(); q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i]) { int j = e[i]; if (dist[t] + w[i] < dist[j]) { dist[j] = dist[t] + w[i]; cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true; if (!st[j]) { q.push(j); st[j] = true; } } } } return false;}int main(){ cin >> n >> m; memset(h, -1, sizeof h); for (int i = 0; i < m; i++) { int a, b, c; cin >> a >> b >> c; add(a, b, c); }
if (spfa()) puts("Yes"); else puts("No"); return 0;}回溯算法
基本思想:把一个原问题拆分成相似的子问题,再用递归来解决。而回溯算法有一个增量构造答案的过程,这个过程通常也用递归实现,只需要明确边界条件,而不需要人脑模拟递归的过程。
回溯算法的逻辑
- 当前操作:枚举
path[i]上填入的字母 - 子问题:构造的部分()
- 下一个子问题:构造的部分()
关于“恢复现场”
在递归到某一“叶子节点”(非最后一个叶子)时,答案需要向上返回,而此时还有其他的子树(与前述节点不在同一子树)未被递归到,又由于 path 为全局变量。若直接返回,会将本不属于该子树的答案带上去,故需要恢复现场。
恢复现场的方式为:在递归完成 dfs(i+1); 后,进行与“当前操作”相反的操作
子集型回溯
集合中的每个元素都有两种情况:选或不选(类似 01 背包) 例:给你一个整数数组
nums,数组中的元素 互不相同 。返回该数组所有可能的子集。 解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
思路 1:从输入角度,枚举选或不选
- 当前操作:枚举第个数选或不选
- 子问题:从下标的数字中构造子集
- 下一个子问题:从下标的数字中构造子集
叶子节点是答案
思路 2:从答案角度,每次都选一个数,枚举选哪个
- 当前操作:枚举一个下标的数字,加入
path[] - 子问题:从下标的数字中构造子集
- 下一个子问题:从下标的数字中构造子集
递归到的每个节点都是答案
组合型回溯
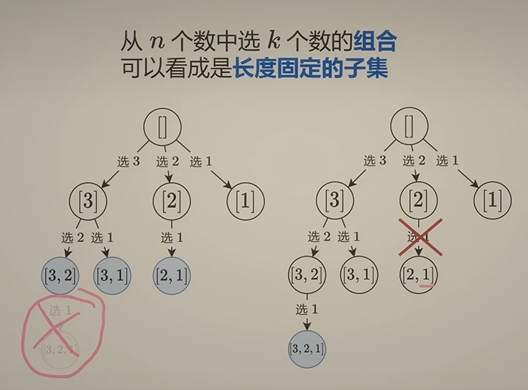
假设 path 长为 m,那么还需要选 d = k - m 个数。假设当前需要从 [1,i] 这 i 个数的区间中选数,如果 i < d,则不可能选出 k 个数,就不需要继续递归,也就是把这部分搜索树剪掉
排列型回溯

DFS
每一个 dfs 过程,都代表一条搜索树。考虑 dfs 时,先考虑最优搜索顺序 本质上,dfs 是用递归函数较快的实现暴力枚举
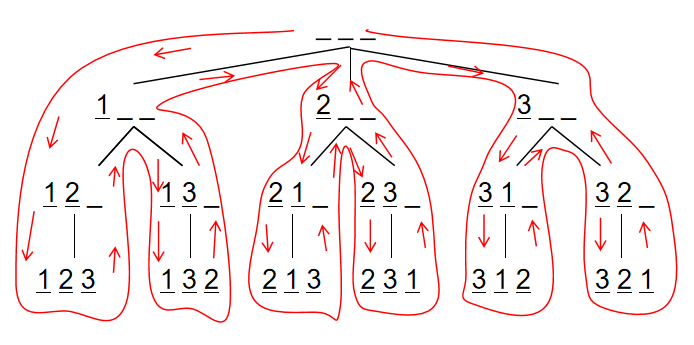
全排列
https://www.acwing.com/problem/content/844/ 给定一个整数 n,将数字 1∼n 排成一排,将会有很多种排列方法。 现在,请你按照字典序将所有的排列方法输出。
用 path 数组保存排列,当排列的长度为 n 时,是一种方案,输出。
用 state 数组表示数字是否用过。当 state[i] 为 1 时:i 已经被用过,state[i] 为 0 时,i 没有被用过。
dfs(i) 表示的含义是:在 path[i] 处填写数字,然后递归的在下一个位置填写数字。
回溯:第 i 个位置填写某个数字的所有情况都遍历后, 第 i 个位置填写下一个数字。
横向枚举,纵向递归
代码
#include <iostream>using namespace std;const int N = 10;
int n;int path[N]; // 存储每条搜索路径bool state[N]; // 存储某个数是否被使用过
void dfs(int u){ if (u == n) // 如果即将要搜索下一个位置,也就是搜满了,输出 { for (int i = 0; i < n; i++) printf("%d ", path[i]); printf("\n"); }
for (int i = 1; i <= n; i++) // 空位上可以选择的数为1~n { if (!state[i]) // 如果没有被用过 { path[u] = i; // 存储路径 state[i] = true; // 记录
dfs(u + 1); // 填下一位
state[i] = false; // 还原现场,回溯并还原i的状态 } }}int main(){ cin >> n; dfs(0); // 从第0位开始搜(path[0]) return 0;}//dfs(3)输出完时return到state[i] = false。//这里i的值是3,i++后for循环条件不满足,跳出。//函数结束。自动返回到上一层递归调用的地方,即dfs(1 + 1);//后面的state[2] = false;,继续判断for循环。n-皇后
https://www.acwing.com/problem/content/845/ n− 皇后问题是指将 n 个皇后放在 n×n 的国际象棋棋盘上,使得皇后不能相互攻击到,即任意两个皇后都不能处于同一行、同一列或同一斜线上。 现在给定整数 n,请你输出所有的满足条件的棋子摆法。
图例
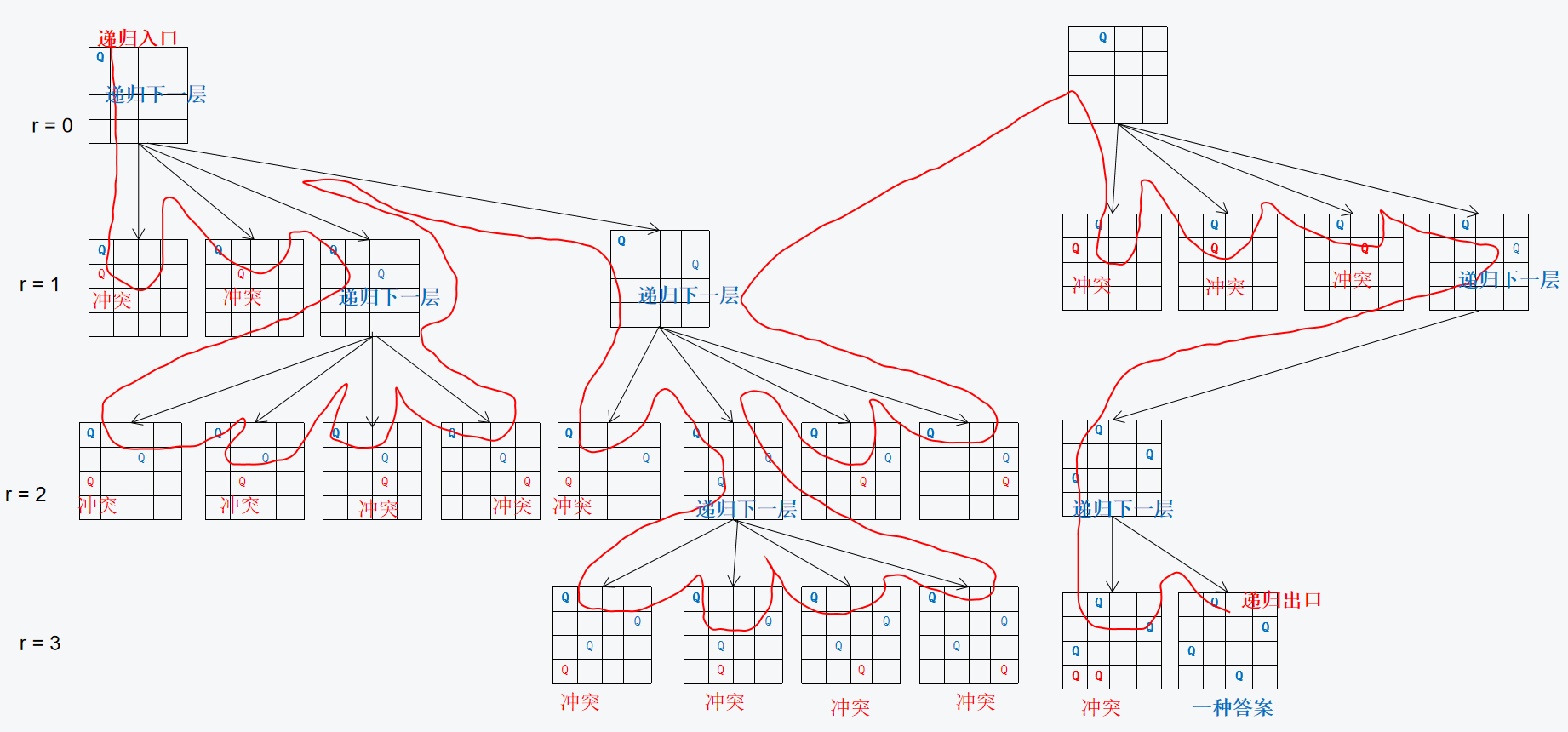
方法 1:枚举每行
思路:注意到每一行有且仅有一个皇后。可以通过枚举每一行的每一个位置,判断列、主副对角线进行搜索
#include <iostream>using namespace std;
const int N = 20;int n;
char g[N][N];bool col[N], dg[N], udg[N]; // 对角线和反对角线
void dfs(int u) // 用u来枚举每一行{ // 递归终止条件 if (u == n) { for (int i = 0; i < n; i++) { for(int j = 0; j < n; j++) { printf("%c", g[i][j]); } printf("\n"); } printf("\n"); return; }
// 枚举第u行的皇后放在哪一列 for (int i = 0; i < n; i++) { if (!col[i] && !dg[u + i] && !udg[n - u + i]) { g[u][i] = 'Q'; col[i] = dg[u + i] = udg[n - u + i] = true;
dfs(u + 1);
g[u][i] = '.'; col[i] = dg[u + i] = udg[n - u + i] = false; } }}int main(){ cin >> n; for (int i = 0; i < n; i++) for (int j = 0; j < n; j++) g[i][j] = '.'; dfs(0); return 0;}方法 2:枚举每格
思路:枚举每一个格子。对于每一个格子,有放皇后和不放皇后两种选择。放皇后需要判断行、列、主副对角线;不放皇后则直接递归到下一个格子
...bool row[N], col[N], dg[N], udg[N];...void dfs(int x, int y, int s){ if (y == n) // 如果搜完某行最后一列出界了,就切到下一行的第0列 y = 0, x++;
if (x == n) // 搜到最后一行 { if (s == n) // 有n个皇后,也就是每行一个皇后 { for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) printf("%c", g[i][j]); printf("\n"); } printf("\n"); return; } }
dfs(x, y + 1, s)
if (!row[x] && !col[y] && !dg[x + y] && !udg[n + x - y]) { g[x][y] = 'Q'; row[x] = col[y] = dg[x + y] = udg[n + x - y] = true;
dfs(x, y + 1, s + 1);
row[x] = col[y] = dg[x + y] = udg[n + x - y] = false; g[x][y] = '.'; }}...dfs(0, 0, 0);dfs 枚举策略
指数型枚举
需要记录每个位置当前的状态,0 表示还没考虑,1 表示选它,2 表示不选它
#include <iostream>using namespace std;
int n;int st[20];
void dfs(int u){ if(u > n) { for(int i = 1; i <= n; i++) { if(st[i] == 1) cout << i << " "; } cout << endl; return; }
st[u] = 1; dfs(u + 1); st[u] = 0;
st[u] = 2; dfs(u + 1); st[u] = 0;}int main(){ cin >> n;
dfs(1); return 0;}排列型枚举
和上文全排列实现思路一模一样,这里给出从 1 开始搜的代码
dfs 需要三个参数:路径 path[N],判重数组 st[N],当前枚举到的位置 u
#include <iostream>using namespace std;const int N = 12;
int n;int path[N];bool st[N];
void dfs(int u){ if(u > n) { for(int i = 1; i <= n; i++) cout << path[i] << " "; cout << endl; return; }
for(int i = 1; i <= n; i++) { if(!st[i]) { path[u] = i; st[i] = true; dfs(u + 1);
path[u] = 0; st[i] = false; } }}
int main(){ cin >> n;
dfs(1); return 0;}组合型枚举
相较于排列型枚举,组合型枚举保证每个方案内部是递增的
对于两个不同的行,字典序较小的排在前面,根据枚举策略,自动实现了字典序
dfs 需要三个参数:
路径 way[N],当前枚举到了哪个位置 u,当前位置最小可以从哪个数开始枚举 start
注:start 初始时为 1,后面的 start=前一位的数 + 1
注:可以进行剪枝,根据上文,start 表示排第一个的数字,而我们需要排 m 个数字,因此在过程中需要保证 start 后面有足够的数字可以排到 m,即:n - start >= m - u,所以不可行的方案就是 n - start < m - u
#include <iostream>using namespace std;const int N = 30;
int n, m;int way[N];
void dfs(int u, int start){ if (n - start < m - u) // 剪枝 return;
if (u == m + 1) { for (int i = 1; i <= m; i++) cout << way[i] << " "; puts(""); return; }
for (int i = start; i <= n; i++) { way[u] = i; dfs(u + 1, i + 1);
way[u] = 0; }}
int main(){ cin >> n >> m; dfs(1, 1); return 0;}BFS
BFS 由于其按层遍历的特性,可以找出“最短路径”。适用条件是图的边权均为 1。
基本框架
- 开一个二维数组,存放整个图(graph)
- 用一个
pair队列,存储距原点距离相同的所有可用点 int d[]存储每个点到原点的距离- 搜索过程中,遍历每个队列里的点,并向四种方向尝试搜索
走迷宫
图例

由于 bfs 的搜索逻辑,第一个到达终点的线路一定最短
代码
// Problem: 走迷宫// Contest: AcWing// URL: https://www.acwing.com/problem/content/846/// Time: 2026-01-23 11:54:04//// Powered by CP Editor (https://cpeditor.org)#include <algorithm>#include <cstring>#include <iostream>#include <queue>using namespace std;
typedef pair<int, int> PII;const int N = 110;
int n, m;int g[N][N]; // 存储整个图int d[N][N]; // 存储距离queue<PII> q; // 存储每一步走到的点(路径)
void bfs(){ memset(d, -1, sizeof(d)); // 设置距离为-1,代表没走过的点
q.push({0, 0}); // 原点为最开始的路径 d[0][0] = 0; // 设置原点的距离为0
int dx[4] = {-1, 0, 1, 0}; int dy[4] = {0, 1, 0, -1};
while (!q.empty()) // 循环依次取出同一步数能走到的点,再尝试往前走一步。 { PII st = q.front(); // 取队头作为起始点 q.pop();
for (int i = 0; i < 4; i++) // 向四个方向尝试走 { int x = st.first + dx[i], y = st.second + dy[i];
// 判断是否走出图,再判断是不是墙,再判断走没走过 if (x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1) { d[x][y] = d[st.first][st.second] + 1; // 此时成功走到了(x,y),所以距离+1
q.push({x, y}); } } }
cout << d[n - 1][m - 1];}int main(){ cin >> n >> m; for (int i = 0; i < n; i++) for (int j = 0; j < m; j++) cin >> g[i][j];
bfs(); return 0;}八数码

思路
把每一种 3*3 矩阵的状态看作一张图的节点,如果状态 A 可以变换到状态 B,则在 AB 之间建边,且权值为 1。此时问题抽象成从起点状态走到终点状态的最短路,使用 BFS。
表示每一种状态:用 string 表示,把 3*3 的矩阵展成 9 个字符的字符串,存入 queue<string>
表示每个状态的“距离”(即移动次数):用 unordered_map<string, int>
判断每个状态可以变成哪些状态(状态转移):
- 把
string恢复成 3*3 的矩阵 - 移动 X,尝试对调 X 和它上下左右四个方向的数
- 把所有 3*3 的矩阵变回
string
代码
// Problem: 八数码// Contest: AcWing// URL: https://www.acwing.com/problem/content/847/// Time: 2026-01-24 10:11:11// unordered_map的底层原理是哈希表,查询O(1),遇到大量查询的情况速度会快些// Powered by CP Editor (https://cpeditor.org)#include <algorithm>#include <iostream>#include <queue>#include <string>#include <unordered_map>
using namespace std;
int bfs(string start){ string end = "12345678x";
queue<string> q; // bfs架构
unordered_map<string, int> d; // 表示每个状态的变换次数
q.push(start); d[start] = 0;
int dx[4] = {-1, 0, 1, 0}; int dy[4] = {0, 1, 0, -1};
while (!q.empty()) { string t = q.front(); q.pop();
int dist = d[t]; // dist和d[t]表示当前状态交换了多少次
if (t == end) // 出现了结果序列 return d[t]; // 返回答案
// 状态转移 int k = t.find('x'); // 找到x的位置,即获取x的下标 int x = k / 3, y = k % 3; // 求出x在矩阵里的横纵坐标(x, y)
for (int i = 0; i < 4; i++) // 枚举四个方向 { int a = x + dx[i], b = y + dy[i]; // 求出x变换后的横纵坐标(a, b)
if (a >= 0 && a < 3 && b >= 0 && b < 3) // 检查越界 { swap(t[k], t[a * 3 + b]); // 状态更新,交换x和某个数字(a*3+b)是(a,b)在一维string里的坐标
if (!d.count(t)) // 如果这个状态没有出现过,即map里没有该状态的距离信息,放入队尾并向哈希表里添加距离 { d[t] = dist + 1; q.push(t); }
swap(t[k], t[a * 3 + b]); // 状态恢复,尝试进行下一个方向的交换 } } }
return -1; // while结束以后没有找到,返回-1}int main(){ string start; for (int i = 0; i < 9; i++) { char c; cin >> c; start += c; }
cout << bfs(start) << endl; return 0;}最短路
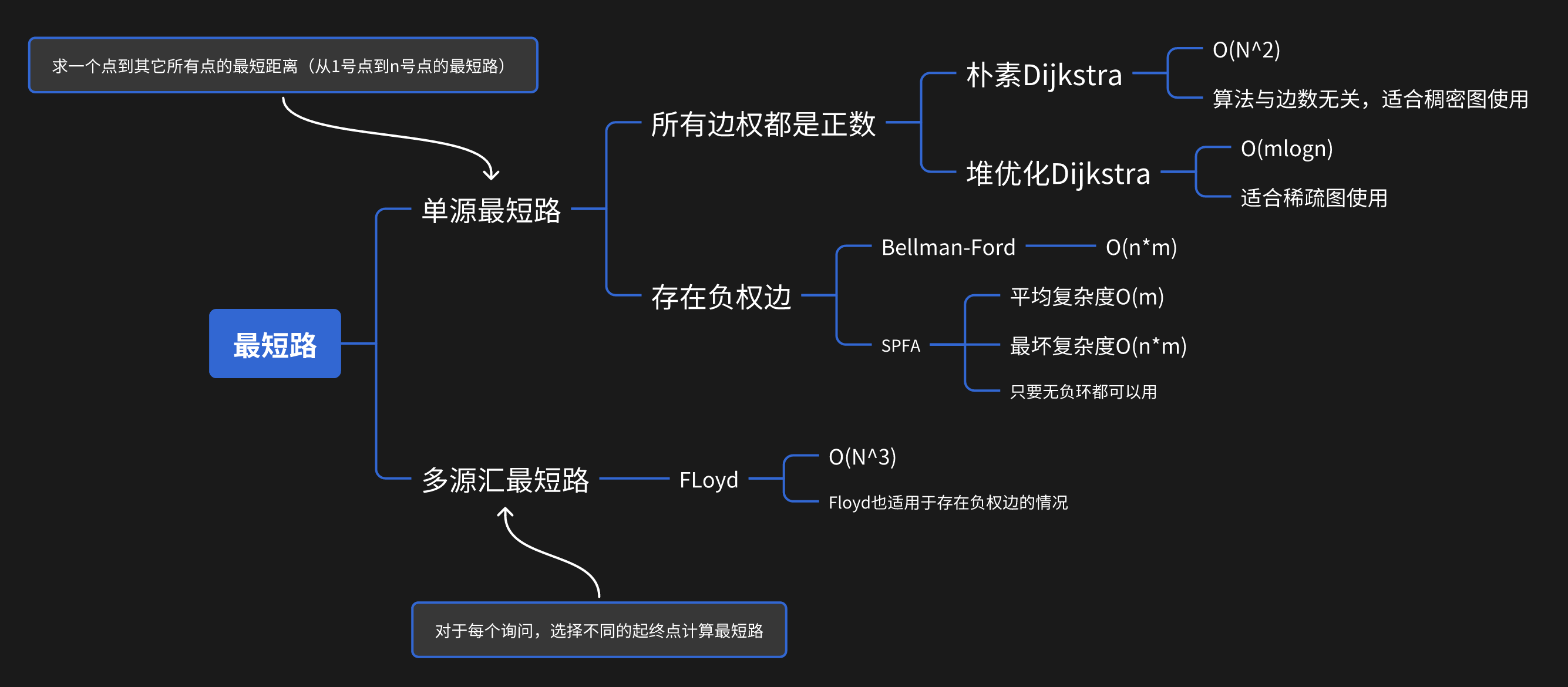
TIP最短路问题的关键在于建图。即如何从实际问题中抽象出最短路问题,如何建点建边 下文约定:一张图中点数为 n,边数为 m
最短路问题的解法框架
注意:无向图是特殊的有向图,在最短路问题中,处理无向图问题建双向边即可
最短路问题中处理重边的方法:在读入边时,只保留长度最小的边
最短路问题中处理自环的方法:直接删去(在邻接矩阵中当 i==j 时,初始化 d[i][j] == 0)
最短路问题中输出时处理负权边的方法:判断距离是否大于和 INF 同一量级的数*(不能判断是否等于INF!)*
Dijkstra
Dijkstra 不能解决负权边是因为:Dijkstra 要求每个点被确定后 st[j] = true,dist[j]就是最短距离了,之后就不能再被更新了,而如果有负权边,已经确定的点的 dist[j]不一定是最短,故无法使用
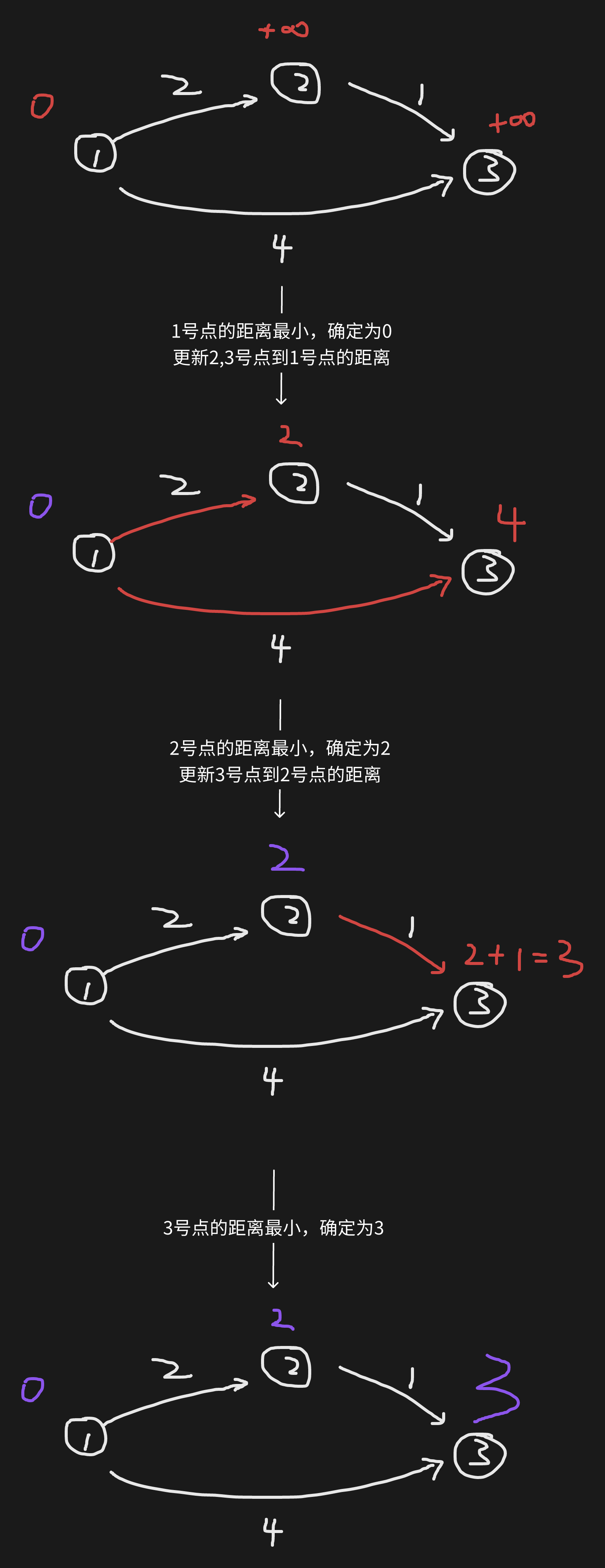
朴素 Dijkstra-适用于稠密图
思路
- 使用
dist[i]表示点 i 到原点的距离,初始化dist[1]=0, dist[i]=INF - 开一个
bool,存储当前已被确定最短距离的点 - 迭代
n次如下操作,找到每个点到起点的最短路:- 找到不在
s中的距离最近的点,用中间变量t存储,把t加到s里 - 用
t来更新t的出边指向的所有点到起点的距离,比较1~i和1~t~i的距离大小 (判断dist[i]是否大于dist[t]+w(t, i))
- 找到不在
图解
代码
// Problem: Dijkstra求最短路 I// Contest: AcWing// URL: https://www.acwing.com/problem/content/851/// Time: 2026-01-24 19:17:53// 本题为无堆优化的Dijkstra,本题存在自环和重边// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
const int N = 510;
int n, m; // 点数和边数int g[N][N]; // 使用邻接矩阵存储稠密图,g[x][y]表示边x->yint dist[N]; // 距离bool st[N]; // 判断每个点的最短路是否已经确定的集合
int dijkstra(){ memset(dist, 0x3f, sizeof(dist));
dist[1] = 0;
for (int i = 0; i < n; i++) // 迭代n次 { int t = -1; // 存储当前访问的点 // 设置为负数,是因为Dijkstra适用于无负权边的图,负数就可以表示还未确定的点
for (int j = 1; j <= n; j++) // 枚举1号点到n号点,寻找还未确定最短路的点中路径最短的点 if (!st[j] && (t == -1 || dist[t] > dist[j])) t = j;
st[t] = true;
for (int j = 1; j <= n; j++) { dist[j] = min(dist[j], dist[t] + g[t][j]); // 更新长度,取1~j和1~t~j长度的最小 } }
if (dist[n] == 0x3f3f3f3f) // 若为正无穷,说明第n个点和第一个点不连通 return -1; else return dist[n];}int main(){ cin >> n >> m;
memset(g, 0x3f, sizeof(g));
while (m--) // 读入m条边 { int a, b, c; cin >> a >> b >> c; g[a][b] = min(g[a][b], c); // 读入时,由于存在重边,则只保留距离最短的边 }
cout << dijkstra() << endl; return 0;}堆优化 Dijkstra-适用于稀疏图
前置知识: 使用小根堆后,找到 t 的耗时从 O(n^2) 将为了 O(1)。每次更新 dist 后,需要向堆中插入更新的信息。所以更新 dist 的时间复杂度有 O(e) 变为了 O(elogn)。总时间复杂度有 O(n^2) 变为了 O(n + elogn)。适用于稀疏图。
思路
- 与朴素 Dijkstra 相同,开一个
dist数组存储距离,bool数组存储已被确定距离的点 - 本方法适用于稀疏图,故使用邻接表存图,并开一个
w[N]存储权重 - 使用小根堆,优化朴素 Dijkstra 中每次找不在 s 中的距离最近的点的过程
- 堆中需要存储距离和节点编号,故使用
pair堆,按照distance建堆 - 每次从堆中取出堆头
heap.top(),获取节点编号ver,距离distance - 判断
st[],如果距离已经被确定过,则continue当次循环 - 遍历
ver为表头的单链表,更新其所有出边所指向的节点距离
- 堆中需要存储距离和节点编号,故使用
代码
// Problem: Dijkstra求最短路 II// Contest: AcWing// URL: https://www.acwing.com/problem/content/852/// Time: 2026-01-25 10:33:43// 本方法无需考虑重边// 用pair堆的原因是:在维护距离是小根堆的同时,需要知道每个点的节点编号// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
typedef pair<int, int> PII;const int N = 100010;
int n, m; // 点数和边数int h[N], e[N], ne[N], idx; // 使用邻接表存储稀疏图int w[N]; // 存储权重int dist[N]; // 距离bool st[N]; // 判断每个点的最短路是否已经确定的集合
void add(int a, int b, int c){ e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++;}
int dijkstra(){ memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap; // 不指定pair的cmp函数时,默认从小到大比第一个元素 heap.push({0, 1});
while (heap.size()) { PII t = heap.top(); heap.pop();
int ver = t.second, distance = t.first; if (st[ver]) continue;
for (int i = h[ver]; i != -1; i = ne[i]) { int j = e[i]; if (dist[j] > distance + w[i]) { dist[j] = distance + w[i]; heap.push({dist[j], j}); } } }
if (dist[n] == 0x3f3f3f3f) // 若为正无穷,说明第n个点和第一个点不连通 return -1; else return dist[n];}int main(){ cin >> n >> m;
memset(h, -1, sizeof h);
while (m--) // 读入m条边 { int a, b, c; cin >> a >> b >> c; add(a, b, c); }
cout << dijkstra() << endl; return 0;}Bellman-Ford
对于边 (𝑢,𝑣),松弛操作对应下面的式子:
𝑑𝑖𝑠(𝑣) =min(𝑑𝑖𝑠(𝑣),𝑑𝑖𝑠(𝑢) +𝑤(𝑢,𝑣))Bellman–Ford 算法所做的,就是不断尝试对图上每一条边进行松弛.每进行一轮循环,就对图上所有的边都尝试进行一次松弛操作,当一次循环中没有成功的松弛操作时,算法停止 需要注意的是,以 𝑆 点为源点跑 Bellman–Ford 算法时,如果没有给出存在负环的结果,只能说明从 𝑆 点出发不能抵达一个负环,而不能说明图上不存在负环(如果有负权环的话,最短路的求解会经过无数次松弛,导致结果可能是负无穷) 若求从 1 号点到 n 号点的最多经过 k 条边的最短距离,只能用该算法
思路
迭代 k 次的含义:从 1 号点经过不超过 k 条边走到所有点的最短距离 故有推论:只要第 n 次迭代有距离更新,则图中存在负环
- 迭代 n 次,每次迭代都遍历 m 条边(a->b 边权 w)
- 更新距离,
dist[b] = min(dist[b], dist[a] + w)
特别地,若最短路问题有边数限制,则应该开一个 backup[],存储每次迭代的结果用于下一次迭代,防止串联效应(用意料之外的点更新了其它点的距离,导致结果有误)
串联效应发生的原理
由于这个算法的特性决定,每次更新得到的必然是在多考虑 1 条边之后能得到的全局的最短路。而串联指的是一次更新之后考虑了不止一条边:由于使用了松弛,某节点的当前最短路依赖于其所有入度的节点的最短路;假如在代码中使用 dist[b]=min(dist[b],dist[a] + w),我们无法保证 dist[a] 是否也在本次循环中被更新,如果被更新了,并且 dist[b] > dist[a] + w,那么会造成当前节点在事实上“即考虑了一条从某个节点指向 a 的边,也考虑了 a->b”,共两条边。而使用 dist[b]=min(dist[b],backup[a] + w),可以保证 a 在 dist 更新后不影响对 b 的判定,因为后者使用 backup 数组,保存着上一次循环中的 dist 的值。
代码
// Problem: 有边数限制的最短路// Contest: AcWing// URL: https://www.acwing.com/problem/content/855/// Time: 2026-01-25 22:48:31//// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
const int N = 510, M = 10010;
int n, m, k;int dist[N]; // 存储距离int backup[N]; // 需要只使用上一次迭代的结果来迭代距离,防止串联,所以存备份
struct Edge // 用结构体存储所有边:a--w-->b{ int a, b, w;} edges[M];
void bellman_ford(){ memset(dist, 0x3f, sizeof dist); dist[1] = 0;
for (int i = 0; i < k; i++) // 迭代k次 { memcpy(backup, dist, sizeof dist); // 存上次迭代的结果
for (int j = 0; j < m; j++) // 遍历m条边 { int a = edges[j].a, b = edges[j].b, w = edges[j].w; dist[b] = min(dist[b], backup[a] + w); } }
if (dist[n] > 0x3f3f3f3f / 2) // INF是一个确定的值,并非真正的无穷大,会随着其他数值而受到影响(被更新) // dist[n]大于某个与INF相同数量级的数即可 printf("impossible"); else cout << dist[n] << endl;}int main(){ cin >> n >> m >> k;
for (int i = 0; i < m; i++) { int a, b, w; cin >> a >> b >> w; edges[i] = {a, b, w}; }
bellman_ford();}SPFA(常用)
SPFA 是 Bellman-Ford 的优化版,只要图中没有负环,都可以使用 SPFA 求最短路 可以解决有负权和没有负权的问题,且在没有负权的图中,速度快于 Dijkstra SPFA 被卡的情况:https://www.acwing.com/file_system/file/content/whole/index/content/7961829/
思路
算法在 Bellman-Ford 的基础上,使用 BFS 进行优化;代码在 Dijkstra 的基础上优化。
注意到如果 dist[b] 要变小,一定是由于 dist[a] 变小了,所以只要一个节点距离变小了,就把它放到队列里,并用这些已经变小的点,来更新其它点。
- 使用一个队列,存储节点距离变小的点,初始时队列里只有起始点
- 使用
st[],记录点的入队情况,提高效率:如果一个点在队列里,它一定会被遍历到,无需重复的push() - 取队头,不断出队,计算 1 号点经过队头点到其他点的距离是否变短,如果变短了,就更新距离,且如果该点不在队列中,则把该点加入到队尾。
代码
// Problem: spfa求最短路// Contest: AcWing// URL: https://www.acwing.com/problem/content/853/// Time: 2026-01-26 17:58:05// spfa只会更新所有能从起点走到的点,遵循拓扑序// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;const int N = 100010;
int n, m;int h[N], e[N], ne[N], idx;int dist[N], w[N];bool st[N];
void add(int a, int b, int c){ e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++;}
void spfa(){ memset(dist, 0x3f, sizeof dist); dist[1] = 0;
queue<int> q; q.push(1); st[1] = true;
while (q.size()) { int t = q.front(); q.pop();
st[t] = false; // 出队
for (int i = h[t]; i != -1; i = ne[i]) { int j = e[i]; if (dist[t] + w[i] < dist[j]) // 更新距离 { dist[j] = dist[t] + w[i]; if (!st[j]) // 如果当前没有在队里,就入队 { q.push(j); st[j] = true; } } } } if (dist[n] == 0x3f3f3f3f) puts("impossible"); else cout << dist[n] << endl;}int main(){ cin >> n >> m; memset(h, -1, sizeof h); for (int i = 0; i < m; i++) { int a, b, c; cin >> a >> b >> c; add(a, b, c); }
spfa(); return 0;}Floyd
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。 再给定 k 个询问,每个询问包含两个整数 x 和 y,表示查询从点 x 到点 y 的最短距离,如果路径不存在,则输出“impossible”。 数据保证图中不存在负权回路。
floyd 本身是个动态规划算法,在代码实现的时候省去了一维状态。
原状态是:f[i, j, k] 表示从 i 走到 j 的路径上除了 i, j 以外不包含点 k 的所有路径的最短距离。那么有
f[i, j, k] = min(f[i, j, k - 1), f[i, k, k - 1] + f[k, j, k - 1])
因此在计算第 k 层的 f[i, j] 的时候必须先将第 k - 1 层的所有状态计算出来,所以需要把 k 放在最外层。
void floyd() { for(int k = 1; k <= n; k++) for(int i = 1; i <= n; i++) for(int j = 1; j <= n; j++) d[i][j] = min(d[i][j], d[i][k] + d[k][j]);}最小生成树
前置知识: 生成树:在无向连通图中求一棵树(n-1 条边,无环,连通所有点) 我们定义无向连通图的最小生成树(Minimum Spanning Tree,MST)为边权和最小的生成树。 研究最小生成树的意义在于:找到一种途径,花最小的成本连通所有点
最小生成树问题的解法框架
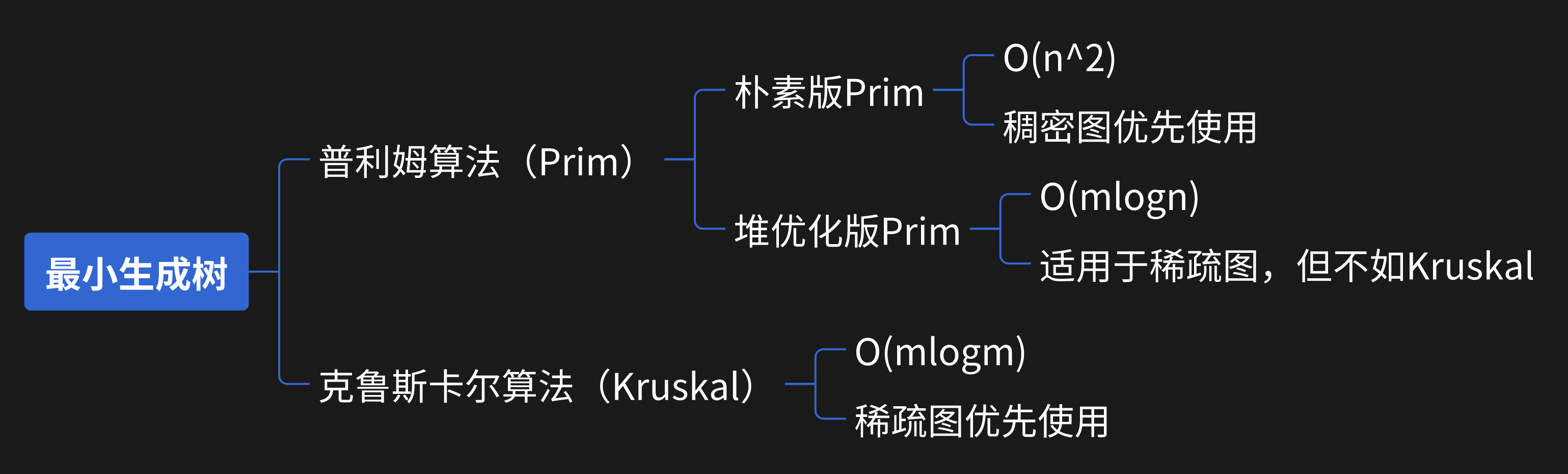
Prim
该算法的基本思想是从一个结点开始,不断加点。具体来说,每次要选择距离最小的一个结点,以及用新的边更新其他结点的距离
思路
- 使用
dist[i]表示点 i 到原点的距离,初始化dist[1]=0, dist[i]=INF - 开一个
bool集合,存储当前已经在集合里的所有点 - 迭代
n次如下操作,- 找到不在集合中的距离最近的点,用中间变量
t存储 - 用
t来更新t的出边指向的所有点到集合的距离 - 把
t加入集合中,st[t] = true
- 找到不在集合中的距离最近的点,用中间变量
- 注:点到集合的距离,定义为这个点到集合内所有点的边权的最小值,若不存在,则为 INF
图例
代码
// Problem: Prim算法求最小生成树// Contest: AcWing// URL: https://www.acwing.com/problem/content/860/// Time: 2026-01-27 10:03:41//// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;const int N = 510, INF = 0x3f3f3f3f;
int n, m;int g[N][N];int dist[N];bool st[N];
int prim(){ memset(dist, 0x3f, sizeof dist);
int res = 0; for (int i = 0; i < n; i++) // 迭代n次,每次循环选出一个点加入到生成树 { int t = -1; for (int j = 1; j <= n; j++) { if (!st[j] && (t == -1 || dist[t] > dist[j])) // 特判第一次迭代 // 如果没有在树中,且到树的距离最短,则选择该点 t = j; }
if (i && dist[t] == INF) // 如果图中存在孤立点,说明没有最小生成树,直接return return INF;
// 需要先累加再更新,避免t有自环,影响答案的正确性 if (i) res += dist[t]; st[t] = true; // 把t点加到生成树里
for (int j = 1; j <= n; j++) // 更新dist dist[j] = min(dist[j], g[t][j]); }
return res;}int main(){ cin >> n >> m; memset(g, 0x3f, sizeof g);
while (m--) { int a, b, c; cin >> a >> b >> c; g[a][b] = g[b][a] = min(g[a][b], c); // 最小生成树针对无向图 }
int res = prim();
if (res == INF) puts("impossible"); else cout << res << endl; return 0;}Kruskal
前置知识: 该算法的基本思想是从小到大加入边,是个贪心算法
思路
- 将所有边按权重从小到大排序
- 使用并查集维护边的集合,记录加入集合的的边的数量
cnt - 从小到大地枚举每条边(a—w—b),如果当前的 a 和 b 两点分属于不同的集合,就把这条边加入生成树中
- 如果
cnt < n-1,说明不存在最小生成树(有 n 个点的树一定有 n-1 条边)
代码
// Problem: Kruskal算法求最小生成树// Contest: AcWing// URL: https://www.acwing.com/problem/content/861/// Time: 2026-01-27 15:09:20//// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
const int N = 200010;
int n, m;int p[N]; // 并查集
struct Edge{ int a, b, w;
// bool operator<(const Edge &W) const // 重载小于号 // { // return w < W.w; // }} edges[N];
bool cmp(struct Edge &a, struct Edge &b) { return a.w < b.w; }int find(int x) // 模板{ if (p[x] != x) p[x] = find(p[x]); return p[x];}int main(){ cin >> n >> m; for (int i = 0; i < m; i++) { int a, b, w; cin >> a >> b >> w; edges[i] = {a, b, w}; }
sort(edges, edges + m, cmp);
for (int i = 1; i <= n; i++) // 初始化并查集 p[i] = i;
int res = 0; // 存储最小生成树的边权和 int cnt = 0; // 存储当前加了多少条边 for (int i = 0; i < m; i++) { int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b); // 查找a和b的根节点
if (a != b) { res += w; cnt++; p[a] = b; } }
if (cnt < n - 1) // 如果一共加的边比n-1少,说明不存在最小生成树 puts("impossible"); else cout << res << endl; return 0;}二分图
二分图,又称二部图,是一类结构特殊的图.它的顶点集可以划分为两个互不相交的子集,使得图中的每条边都连接这两个集合之间的一对点,而不会连接同一集合内部的点 图中点通过移动能分成左右两部分,左侧的点只和右侧的点相连,右侧的点只和左侧的点相连。 得益于这种简单的结构,二分图不仅展现出许多优雅的性质,也广泛应用于现实生活中的建模场景,例如任务分配、推荐系统、匹配市场等.许多在一般图上困难的优化问题,在二分图上都可以高效、准确地求解
二分图的性质
二分图也可以由下列性质等价地定义:
- 图是可以 2‑染色的,也就是说,可以用至多两种颜色给图的所有顶点染色,并且保证相邻顶点颜色不同
- 图中不存在奇数长度的环
染色法
时间复杂度:O(n+m) 由于二分图中没有奇数环,染色过程一定是没有矛盾存在的。同理,如果图中有奇数环,则一定不能被正确地用两种颜色着色
思路
- 遍历顶点,如果发现没有染色的顶点,说明发现了新的连通分量
- 任选一种颜色给该点染色,并以它为起点做深度优先或广度优先遍历,尝试给整个连通分量染色
- 遍历相邻的顶点时,如果发现已经染色的顶点,检查颜色是否与当前顶点相同.相同,则不是二分图,直接返回;否则,继续遍历
- 如果发现尚未染色的顶点,将尚未染色的顶点染上与当前顶点相反的颜色
代码
// Problem: 染色法判定二分图// Contest: AcWing// URL: https://www.acwing.com/problem/content/862/// Time: 2026-01-27 20:44:12// dfs过程中只要返回了false,就说明有矛盾存在,无法被染色// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
const int N = 100010, M = 200020;
int n, m;int h[N], e[M], ne[M], idx;int color[N];
void add(int a, int b){ e[idx] = b; ne[idx] = h[a]; h[a] = idx++;}
bool dfs(int u, int c){ color[u] = c;
for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (!color[j]) { if (!dfs(j, 3 - c)) // (3 - 1 = 2, 如果 u 的颜色是2,则和 u 相邻的染成 1) // (3 - 2 = 1, 如果 u 的颜色是1,则和 u 相邻的染成 2) return false; } else if (color[j] == c) return false; } return true;}int main(){ cin >> n >> m; memset(h, -1, sizeof h);
while (m--) { int a, b; cin >> a >> b; add(a, b), add(b, a); }
bool flag = true;
// 如果有三个点另外成环,整个环是一个孤立环,其他都满足二分图,但是这个孤立的环不满足二分图 // 所以需要遍历所有点 for (int i = 1; i <= n; i++) { if (!color[i]) // 如果没染色 { if (!dfs(i, 1)) // 染色该点,并递归处理和它相邻的点 { flag = false; break; } } }
if (flag) puts("Yes"); else puts("No");
return 0;}匈牙利算法
前置知识: 二分图的匹配:给定一个二分图 G,在 G 的一个子图 M 中,M 的边集 {E} 中的任意两条边都不依附于同一个顶点,则称 M 是一个匹配。(不存在两条边是共用了一个点的) 二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。 理论 O(mn),实际运行时间一般远小于 O(mn)
图解
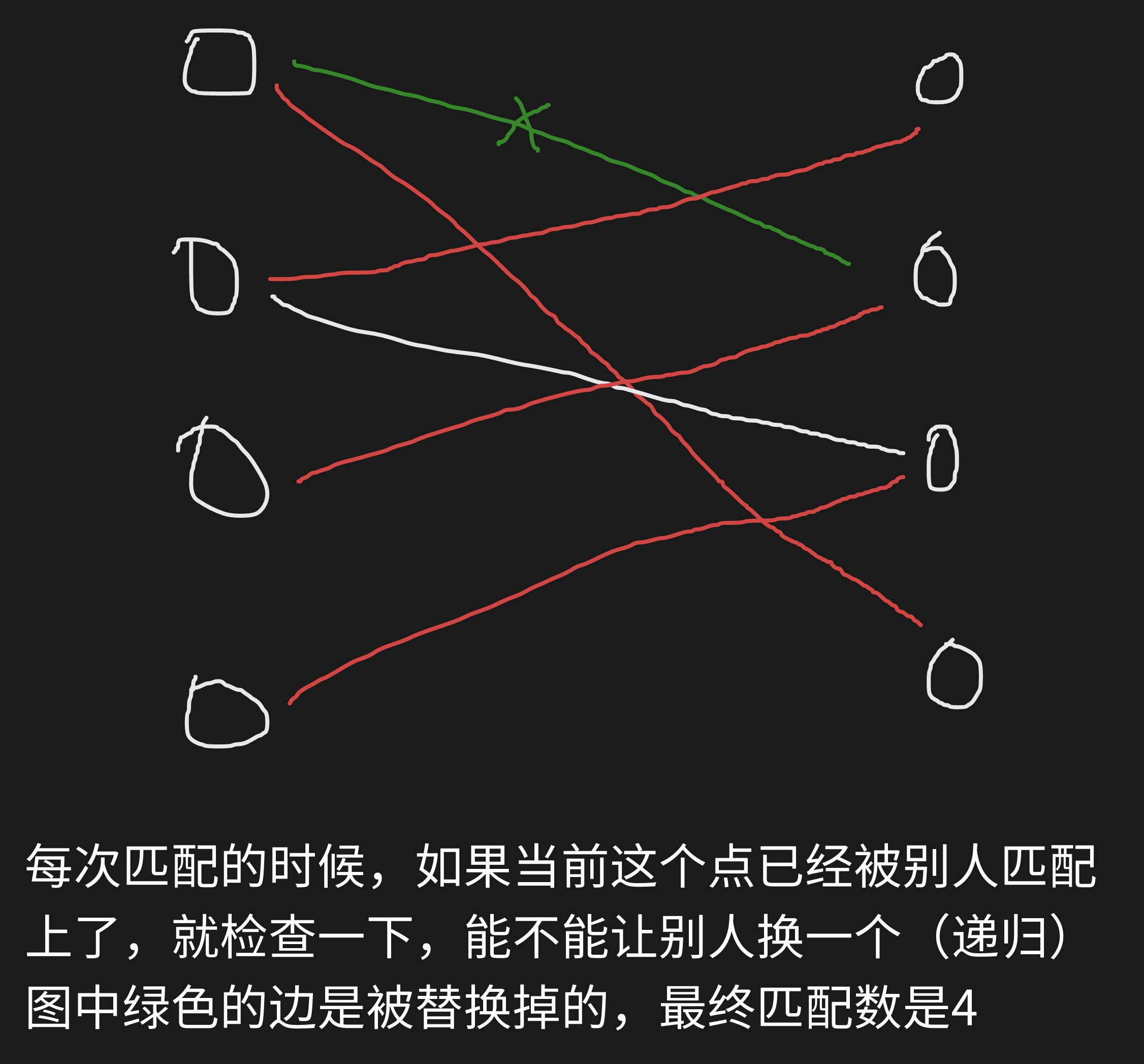
思路
虽然二分图是无向图,但存边的时候,只要存储一条边即可
- 遍历二分图左半部所有点
- 对于左半部的每个点,遍历它指向的所有点(所有出边)
- 预匹配(
bool st[]):如果在这一轮模拟匹配中,右半部的某个点尚未被“预匹配”,那么就建立“预匹配”关系**(预匹配的作用:避免女生 j 的现男友 k 去找备胎的时候,又去找到这个 j)** - 匹配(
int match[]):如果右半部的这个点没有匹配过,或和它预匹配的点可以匹配其它右半部的点,配对成功,更新match[]
代码
// Problem: 二分图的最大匹配// Contest: AcWing// URL: https://www.acwing.com/problem/content/863/// Time: 2026-01-27 22:02:55//// Powered by CP Editor (https://cpeditor.org)#include <bits/stdc++.h>using namespace std;
const int N = 510, M = 100010;
int n1, n2, m;int h[N], e[M], ne[M], idx;int match[N]; // 存储匹配关系。match[j]=a,表示女孩j的现有配对男友是abool st[N]; // 存储预匹配关系。st[j]=a表示一轮模拟匹配中,女孩j被男孩a预定了。
void add(int a, int b){ e[idx] = b; ne[idx] = h[a]; h[a] = idx++;}
bool find(int x){ for (int i = h[x]; i != -1; i = ne[i]) { int j = e[i]; if (!st[j]) // 预匹配关系 { st[j] = true; if (match[j] == 0 || find(match[j])) // 如果女孩j没有男朋友,或者她原来的男朋友能够预定其它喜欢的女孩。配对成功,更新match { match[j] = x; return true; } } } return false;}int main(){ cin >> n1 >> n2 >> m; memset(h, -1, sizeof h);
while (m--) { int a, b; cin >> a >> b; add(a, b); }
int res = 0; // 匹配数量 for (int i = 1; i <= n1; i++) { memset(st, false, sizeof st); // 因为每次模拟匹配的预定情况都是不一样的,所以每轮模拟都要初始化
if (find(i)) res++; }
cout << res << endl; return 0;}